In this article we give the information about normalization in a database design technique that organizes tables in a manner that reduce redundancy (useless) and dependency of data.
Normalization in Database
Definition:
Normalization is the process of organizing data in a database to reduce data redundancy and improve data integrity.
It divides large tables into smaller related tables and connects them using primary keys and foreign keys.
Why Normalization Is Needed
- To eliminate redundant (duplicate)
- To avoid anomalies (Insertion, Update, Deletion).
- To make the database efficient and easy to maintain.
Anomalies
| Type | Meaning | Example Result |
| Insertion Anomaly | Unable to insert data due to missing fields. | Student table does not allow null values. |
| Update Anomaly | Updating one record requires updating multiple records. | Updating dept=’BCA’ for Roll_No=1 updates two rows. |
| Deletion Anomaly | Deleting one record may delete important related data. | Deleting Roll_No=1 deletes two rows. |
Anomaly (Insertion, Update, Delete)
Anomaly: Something that is not according to standard or normal
Student Table
| Roll_No | Name | Address | Dept |
| 1 | Rahul | Pune | BCA |
| 1 | Rahul | Pune | BA |
| 2 | Pranav | Satara | MBA |
| 3 | Geeta | Sangli | BCA |
| 3 | Geeta | Sangli | BA |
- INSERT Statement
INSERT INTO student (Roll_No, Name, Address) VALUES (4, ‘Amol’, ‘Satara’);
Explanation:
- You tried to insert data for columns: Roll_No, Name, Address
- But Dept column is missing.
If Dept column is defined as NOT NULL in the table structure (which means it must have a value), then inserting a record without Dept will cause an error.
Result:
Error: student does not allow null values
(You must specify a value for the Dept column.)
Correct Insert:
INSERT INTO student (Roll_No, Name, Address, Dept)
VALUES (4, ‘Amol’, ‘Satara’, ‘BCA’);
- UPDATE Statement
UPDATE student SET Dept = ‘BCA’ WHERE Roll_No = 1;
Explanation:
- There are two rows where Roll_No = 1 (Rahul, Pune — with Dept ‘BCA’ and ‘BA’).
- This query changes both of them to Dept = ‘BCA’.
Result:
2 rows updated.
Table after UPDATE:
| Roll_No | Name | Address | Dept |
| 1 | Rahul | Pune | BCA |
| 1 | Rahul | Pune | BCA |
| 2 | Pranav | Satara | MBA |
| 3 | Geeta | Sangli | BCA |
| 3 | Geeta | Sangli | BA |
- DELETE Statement
DELETE FROM student WHERE Roll_No = 1;
Explanation:
- There are two rows where Roll_No = 1.
- The DELETE command removes all rows satisfying the condition.
Result:
2 rows deleted.
Table after DELETE:
| Roll_No | Name | Address | Dept |
| 2 | Pranav | Satara | MBA |
| 3 | Geeta | Sangli | BCA |
| 3 | Geeta | Sangli | BA |
Normalization Types:
Here are most commonly used normal forms:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3 NF)
- Boyce & Codd Normal Form (BCNF)
- Forth Normal Form (4NF)
- Fifth Normal Form (5NF)
Example Table:
| Roll_No | Name | Address | Dept |
| 1 | Rahul | Pune | BCA |
| 1 | Rahul | Pune | BA |
| 2 | Pranav | Satara | MBA |
| 3 | Geeta | Sangli | BCA |
| 3 | Geeta | Sangli | BA |
1First Normal Form (1NF)
Rules:
- Each attribute must contain atomic (indivisible)
- No repeating groups or multiple values in a single column.
- Each record must be unique.
Example (Not in 1NF):
| Roll_No | Name | Mobile_No | Dept |
| 2 | Amol | 9865326589, 9965832658 | BA |
Problem: Multiple mobile numbers in one cell (not atomic).
After 1NF:
| Roll_No | Name | Mobile_No | Dept |
| 2 | Amol | 9865326589 | BA |
| 2 | Amol | 9965832658 | BA |
Now every field holds atomic values.
2 Second Normal Form (2NF)
Rules:
- Must be in 1NF.
- All non-key attributes must be fully dependent on the entire primary key.
- No partial dependency.
Example (Not in 2NF):
| Emp_ID | Qualification | Age |
| 101 | BCA | 20 |
| 101 | MCA | 20 |
| 102 | BCom | 21 |
| 102 | MBA | 21 |
Composite Primary Key: (Emp_ID + Qualification)
Non-Key Attribute: Age
Problem: Age depends only on Emp_ID, not on the full key. → Partial dependency
After 2NF:
Table 1: Employee
| Emp_ID | Age |
| 101 | 20 |
| 102 | 21 |
| 103 | 22 |
| 104 | 23 |
Table 2: Emp_Qualification
| Emp_ID | Qualification |
| 101 | BCA |
| 101 | MCA |
| 102 | MBA |
| 104 | MSW |
Now, non-key attributes depend entirely on the primary key.
Third Normal Form (3rd NF):
- It is in second normal form.
- There is no transitive functional dependency.
- A transitive functional dependency is when changing a non-key column, might clause any of the other non-key column to change.
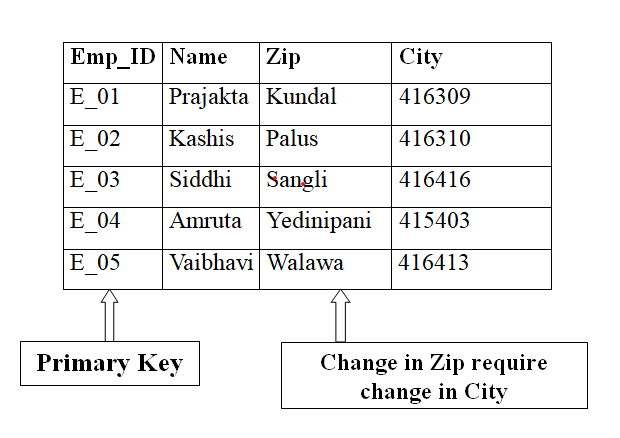
Here,
Emp_ID-> Zip-> City that is City depend on zip and zip depend on Emp_ID
Emp_ID-> City City dependent on Emp_ID
City Indirectly depend on Emp_ID is called transitive functional dependency.
After Third Normalization;
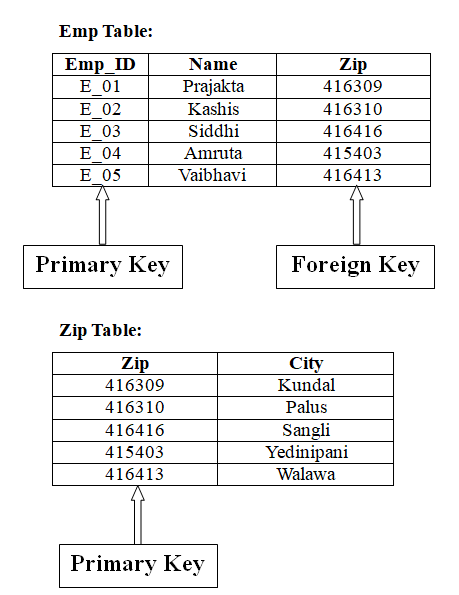
4 Boyce–Codd Normal Form (BCNF)
Definition:
A relation is in BCNF if, for every functional dependency (X → Y),
X is a super key.
Example (Not in BCNF):
| student_id | course | instructor |
| 101 | DBMS | Prof. A |
| 102 | OS | Prof. B |
| 103 | DBMS | Prof. A |
| 104 | CN | Prof. C |
FDs:
- student_id → course
- course → instructor
Here, course is not a super key → violates BCNF.
Decomposition:
R1(course, instructor)
R2(student_id, course)
Both relations now satisfy BCNF.
Another Example:
| Student_ID | Hostel_No | Warden_Name |
| 101 | H1 | Mr. A |
| 102 | H2 | Mr. B |
| 103 | H1 | Mr. A |
| 104 | H3 | Mr. C |
FDs:
- Student_ID → Hostel_No
- Hostel_No → Warden_Name
Here, Hostel_No is not a super key → not in BCNF.
After Decomposition:
R1(Hostel_No, Warden_Name)
R2(Student_ID, Hostel_No)
Both in BCNF.
5 Fourth Normal Form (4NF)
Definition:
A relation is in 4NF if:
- It is in BCNF, and
- It has no non-trivial multi-valued dependencies (MVDs) other than candidate keys.
Notation:
X →→ Y (X multi-determines Y)
Example (Not in 4NF):
| Student | Hobby | Language |
| Ram | Music | Hindi |
| Ram | Music | English |
| Ram | Sports | Hindi |
| Ram | Sports | English |
MVDs:
- Student →→ Hobby
- Student →→ Language
Hobby and Language are independent → violates 4NF.
After 4NF Decomposition:
R1(Student, Hobby)
R2(Student, Language)
Now the relation is in 4NF.
Advantages of Normalization
| Advantage | Description |
| Eliminates Redundancy | Removes duplicate data and saves storage. |
| Ensures Data Integrity | Updates remain consistent across tables. |
| Reduces Anomalies | Prevents insertion, update, and deletion errors. |
| Saves Storage Space | Less duplication → more efficient memory use. |
| Improves Maintenance | Easy to modify and manage the database. |
| Improves Query Efficiency | Well-structured tables can improve query performance. |
| Supports Constraints | Enhances use of primary keys, foreign keys, and unique constraints. |
Final Summary Table
| Normal Form | Condition | Removes |
| 1NF | Atomic values, unique records | Repeating groups |
| 2NF | Full functional dependency | Partial dependency |
| 3NF | No transitive dependency | Transitive dependency |
| BCNF | Every determinant is a super key | Redundant dependencies |
| 4NF | No multi-valued dependency | Multi-valued dependency |
Some More:
POP- Introduction to Programming Using ‘C’
OOP – Object Oriented Programming
DBMS – Database Management System
RDBMS – Relational Database Management System
Join Now: Data Warehousing and Data Mining